





I’m sharing my startup stories while building out my latest project – Calenzen – fixes the meetings you’re invited to so you can always instantly click-to-dial. No special apps, calendar programs, or software is ever needed. Learn more about Calenzen.
My Problem, But Not The Problem
The idea behind this project came after a job interview. I wanted to send the hiring manager a follow-up email, but I never got his address. I spent a few minutes with a search engine looking for “example.com email address formats” and similar searches. It didn’t take long to find what I was looking for. Drilling into the search results it showed a clear pattern of “first.last@example.com.”
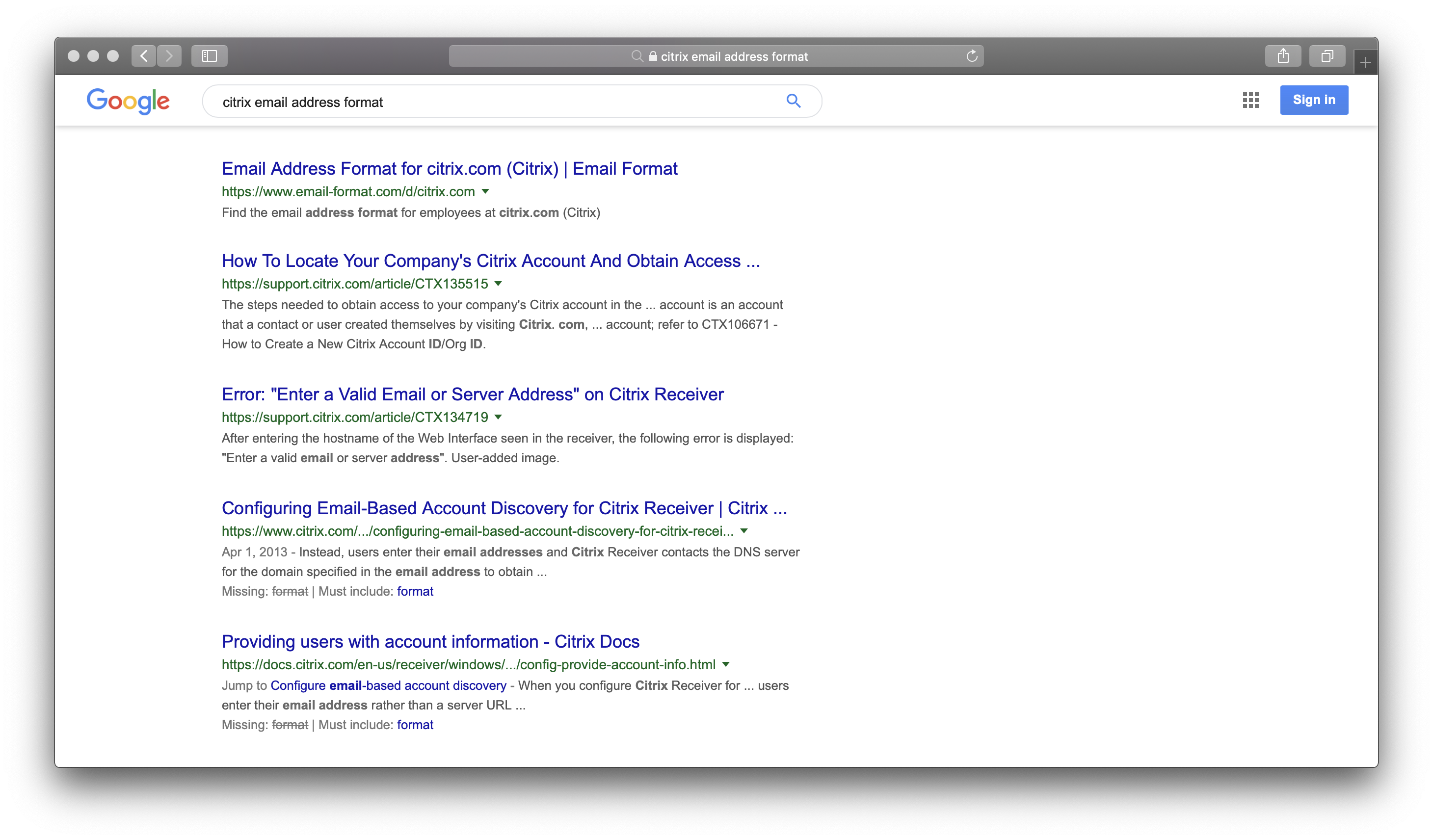
The next day I spent a couple hours pondering how to automate this process. Weren’t there people in the same situation, looking to make a good final impression after an interview?
I envisioned a web site that would do this work for me, so visitors could instantly find the email address format in use at every company. It seemed easy enough that after just one evening hacking on code I could already see real results.
The Real Problem
This project is a success story, to be sure. I’ll take you through all the gory details soon enough, but I’d be remiss if I left my earlier vision of “the problem to be solved” as anything near commonplace. As the project grew, my understanding of actual customer drivers matured.
The typical visitor to my email format website wasn’t looking for a resource to use as a one-time lookup. They were using the site as a resource for complete customer contact information as part of lead generation campaigns.
Most visitor traffic came from repeat visitors, not organic, and it came primarily from off-shore sources. In talking to customers, they were looking for lower cost access to data than is already available from other resources. The cost difference was easily one or two orders of magnitude.
The Solution
Whatever the problem visitors to the email-format.com web site are looking to solve, the solution ultimately remains the same. In the ten years this site has been running, it has gone through three major iterations.
With each new version the UI, underlying technical model, and even the commercial model adapted to take advantage of changing traffic trends.
Version 1, Where it all Began
I started this project questioning how best to get the data I needed. There was no way I’d consider any solution that required ongoing manual effort, so manual data collection was out of the question. Additionally, given email-format.com’s long-tail nature, each piece of data itself wasn’t too valuable. Therefore the revenue model couldn’t support paying for data sourced by another party.
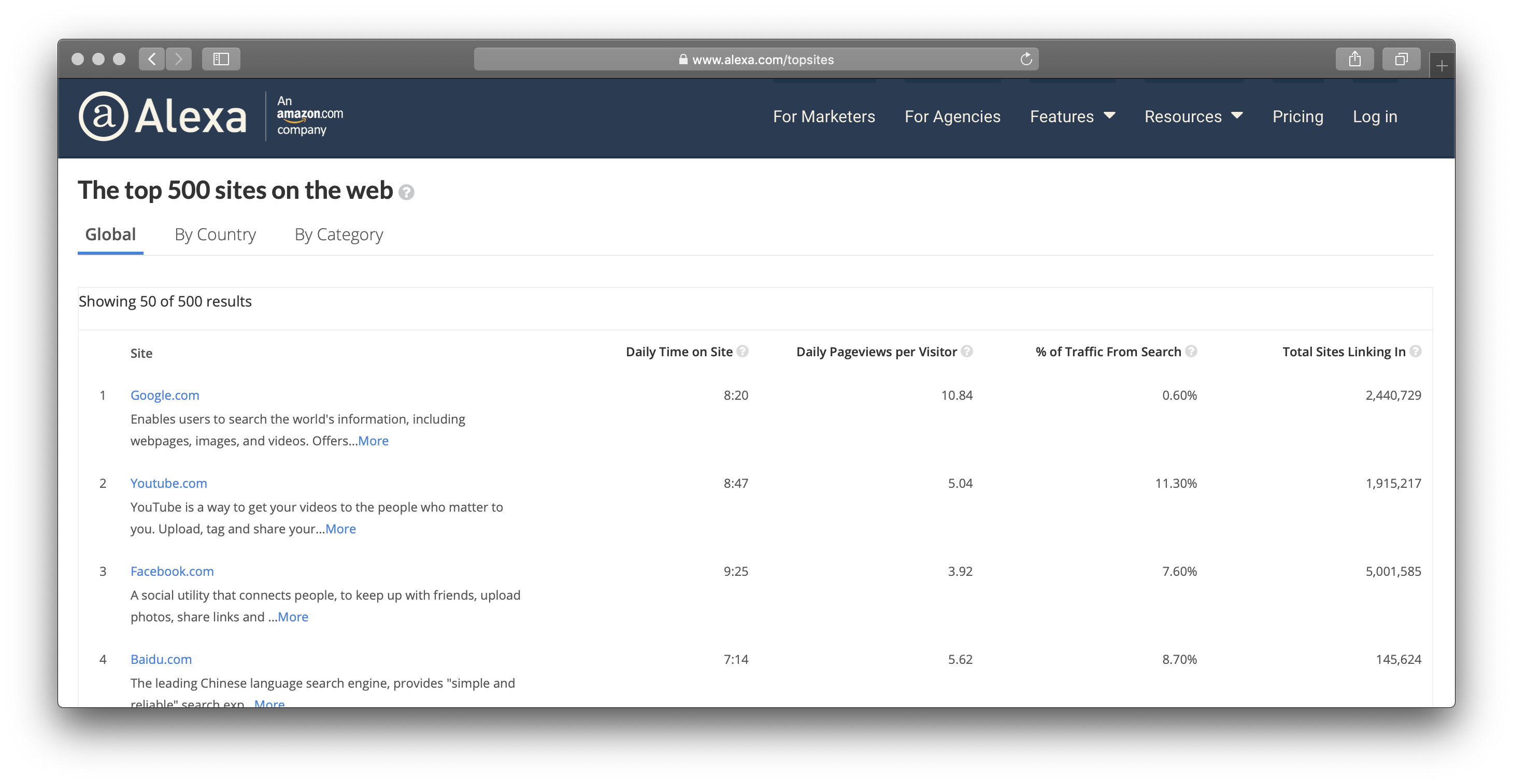
The first thing I needed was a list of interesting domains. Ideally, a zone transfer of the entire .com database (which of course isn’t available). Failing that, I found a friend in the Alexa top sites database. This offered a publicly accessible csv containing the top 1000 .com sites.
A thousand domains is a start of course. And with that, the second thing I needed was to get the email address formats associated with these domains. I wasn’t about to create my own Google-style web index. But maybe I could take advantage of someone else’s?
At the time all major search engines – Yahoo, Bing, and Google – allowed limited API access to their search indexes. Yahoo’s offering was particularly attractive, permitting something on the order of 10,000 monthly searches without charge. Given that individual data points weren’t particularly valuable, any paid API access could never have been profitable, especially since only a small subset of search result pages contained email addresses to analyze.
While staying within these small search limits, I slowly indexed all email addresses associated with those top Alexa sites. That meant I needed a new source of domains. But how could I tell what new domains existed? And more importantly, of the millions of domains not yet in my index, how could I tell which ones would be the most valuable?
I solved this with a neat plugin called the “Job-a-Matic” from simplyhired.com This was a snippet of JavaScript code that would run with each site visit that showed the visitor a list of available jobs. If anyone clicked on a link and was hired, my website would get a small referral fee.
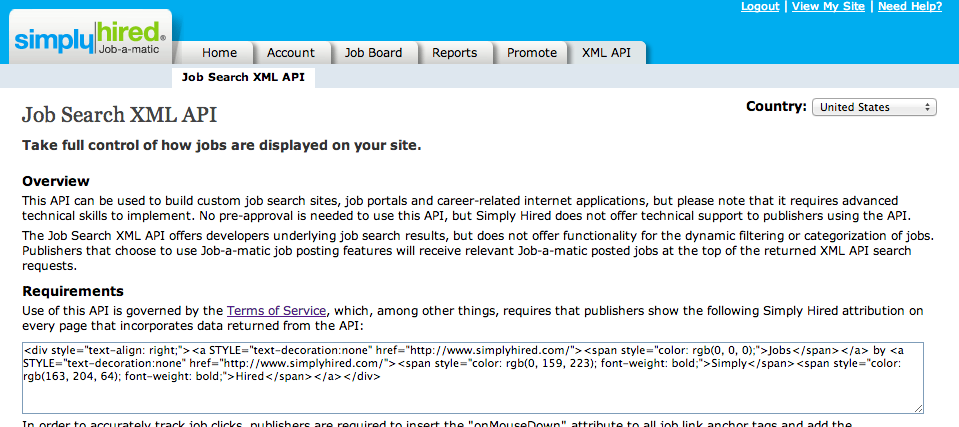
While I was never paid out for referrals, I did get access to continual stream of “hot” companies. Remember – at this point I’m still focussing on the niche use case of job hunters looking to connect with someone they know at a company, but whose email address they don’t have. In this context that means the companies (and therefore domains) to focus on should be actively recruiting.
So using the “Job-a-matic,” I had a fresh stream of target domains that I could burn my no-charge Yahoo API search credits on.
I built all of this over the course of a few evenings and didn’t give it a second thought for a long time. Traffic was low, and ad click through rate was even lower. Google AdSense owed me a few pennies, but they would not pay out until I reached $100 or more, which at the time was an insurmountable threshold.
One day, after almost two years, traffic had increased enough that AdSense advertising was actually cutting a monthly check. Out of nowhere I got an email from Google saying a check was in the mail.
Traffic increased slowly, but was very steady. The site was the top search result for a number of highly trafficked domains so when visitors searched for “email address format at example.com,” my site was the top hit.
Version 2, Scaling Revenue
Over the next 18 months as traffic grew, the total revenue from advertising grew as well. While advertising was bringing in $200 or $300 a month, I was looking to increase that by an order of magnitude.
My strategy was more domains, leads to more traffic, which drives my banner ad click throughs. You don’t have to be a genius to see that for a long-tail site like email-format.com, increasing your overall footprint will bring in more traffic.
Getting Big Data for a Low Price
After a bit of research, I stumbled upon the Common Crawl Database. It was a fully accessible and searchable index of all the web pages they’ve crawled. This data set was like having my own personal Google index (without any of those fees and limits that originally sent me towards Yahoo).
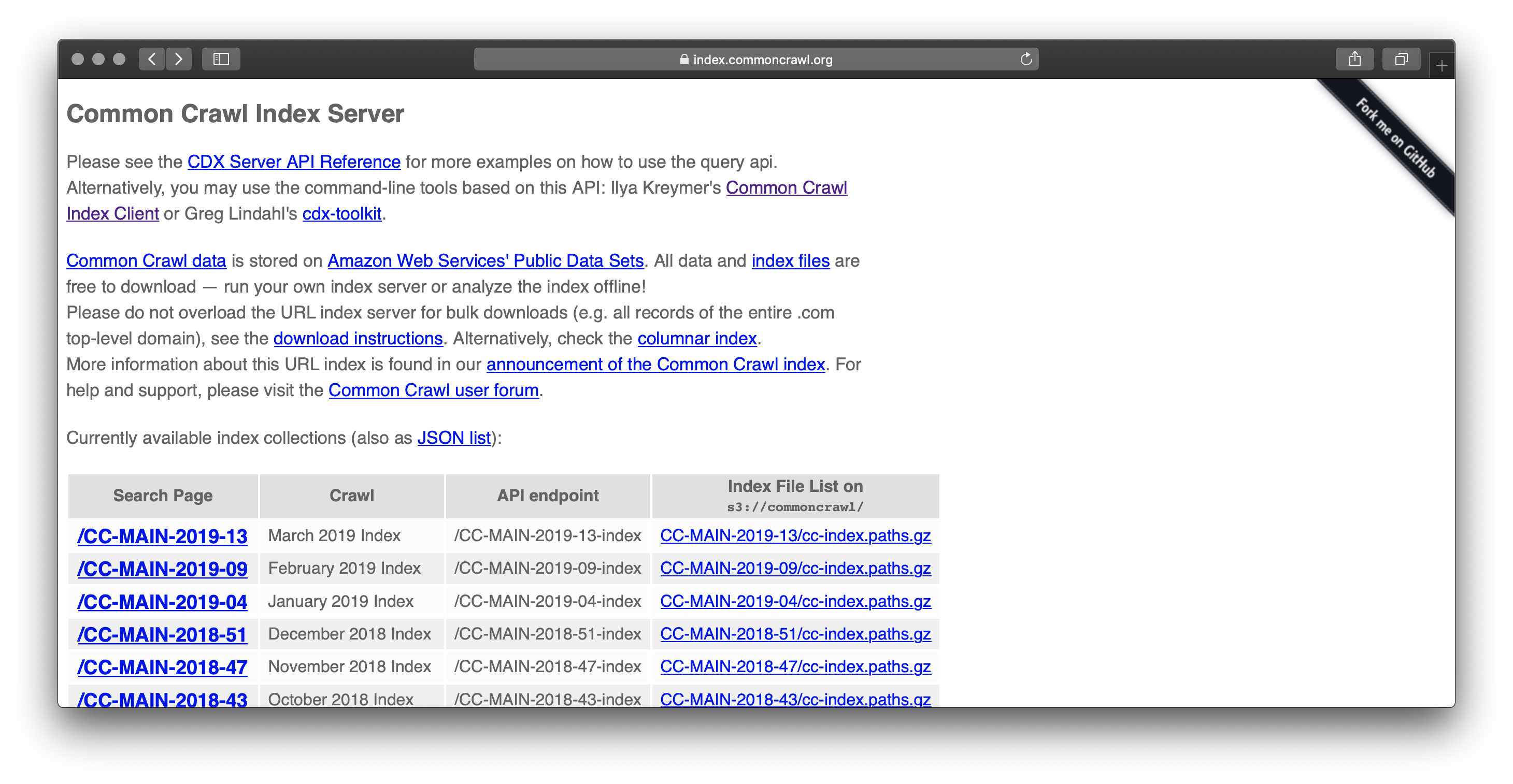
This database contained tens of terabytes of data. All just sitting there for me to scan. There was a catch though – there’s always a catch! The Common Crawl index was hosted on Amazon S3 and downloading the content would cost a nickel for every GB – a potential cost of thousands of dollars.
The clear options were to either pay the network transport fee and process the data on my low cost server or to process the data directly on Amazon AWS compute instances and pay for the relatively expensive compute time but get a free ride on the network transport charges. Given my total monthly expenses to keep the site up were less than $50, either option would quickly run into the multiple thousands of dollars range.
This seemed like a big commitment. Wasn’t there the risk that I wouldn’t find new domains and email addresses? What if the traffic didn’t come?
It was time to take a break from the idea. While revisiting a few weeks later I had a stroke of genius. My plan was to process the Common Crawl web index on a special class of AWS hosted compute servers. This meant zero network transport charges to access terabytes of data.
Instead of paying the rack rate for compute, I would take advantage of a broken marketplace Amazon ran that allowed you to bid on access to excess capacity for a discounted hourly rate. This allowed me to get compute resources for $0.10/hour instead of $1.50 or more. The downside is that if anyone else needed access to the resources, and they were willing to pay even an extra couple cents, then my computer would instantly terminate losing all progress.
I spent a few nights building my own cluster manager that operated outside of this ephemeral “spot” compute instances from Amazon. Once complete the processing flow looked like the following:
- I broke the entire Common Crawl database into 10,000 small segments and stored this on a master server.
- Booted up a pool of 5 new servers on Amazon to act as my worker nodes.
- When each new instance booted up, it would reach out to the central master requesting a small segment of work. When the work was completed, it would submit its list of emails and domains back to the master. A Gigabyte of source data would easily be reduced down to a 100KB or less
- When servers were inevitably terminated, my master server would eventually release the lock those worked nodes had and would reassign it elsewhere
After quickly piecing together an analytics dashboard, I got visibility into the rate of work being completed and I was growing impatient.
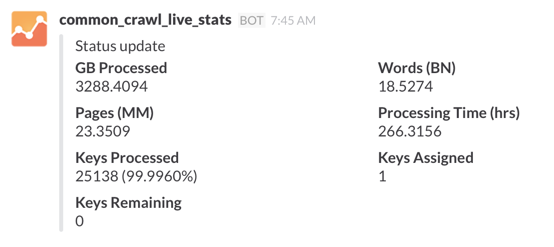
The first phase of scanning was performed using this Amazon compute, but running only a handful of instances would still take two weeks or more to complete. After quickly doing the math, I scaled up to 150 instances and before long, double that. The entire scanning operation was completed in an evening.
Creating More Valuable Data with Some Smart Algorithms
With so much data, I finally had the opportunity to do more than just show a handful of representative email addresses and let site visitors guess how to extrapolate that for their own uses. It was time to level up and actually show the email address formats!
I started by developing a suite of rules for how email addresses might be formatted. These rules covered the basics, like:
- firstname . lastname
- first initial . lastname
- lastname
- etc.
Next, I needed a list of names. I found a list of all registered voters across the state of Ohio which contained millions of first names and surnames.
My name format algorithm would run against every domain containing a sufficient number of representative email addresses. It mashed every email address against every combination of names and compared across the dozen-plus naming rules I’d created. At the end of this pipeline the algorithm spit out a score that showed a confidence rating – just how likely does this email address map to the specified format?
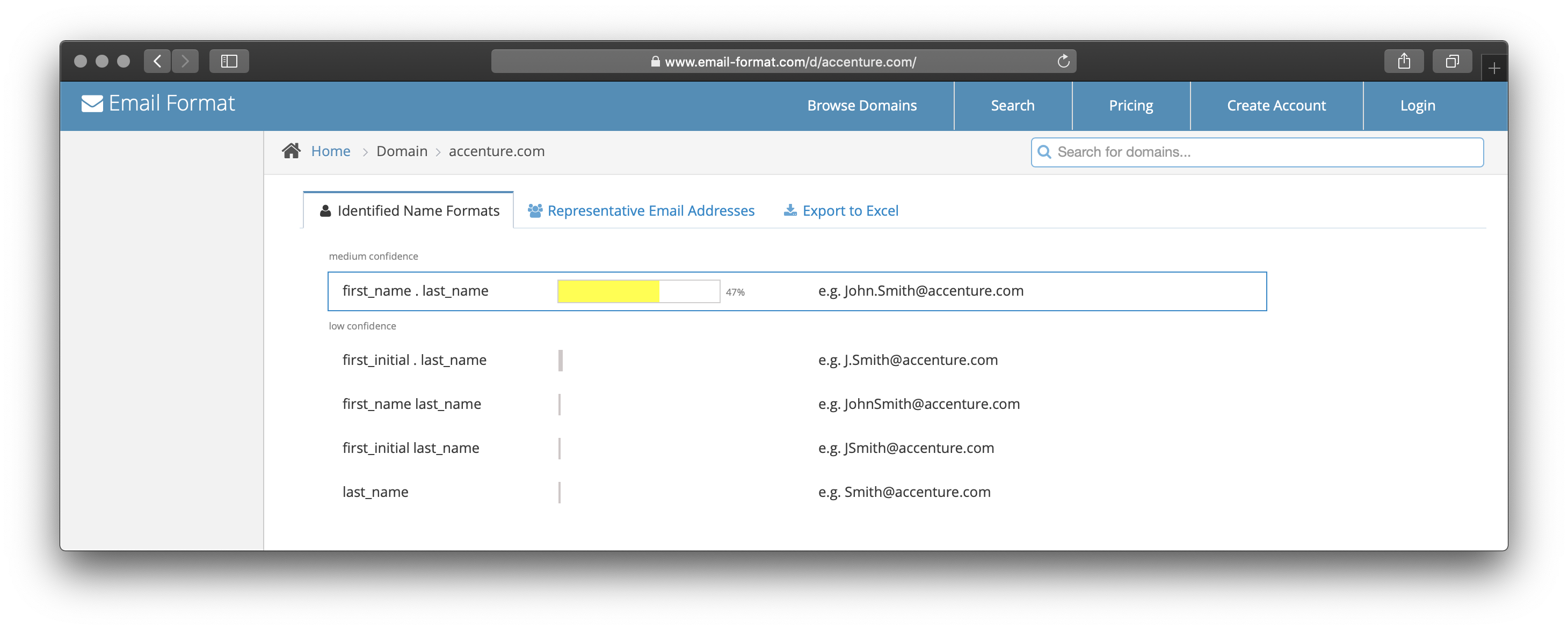
The long tail on this new set of data was amazing and the search engine traffic skyrocketed, along with Adsense revenue. It was at this point that Google Analytics began to show a trend change away from organic traffic towards repeat visitors. They saw the value of knowing the exact address format. Now that I had coverage of hundreds of millions of domains, my new visitors also came to rely on email-format.com by name. The site had clearly become a universal clearinghouse for email address formats.
Stay tuned for the next installment coming out in just two days. Learn how I capitalized on this new data with a whole new customer segment. At the same time, higher-touch sales requests, integration opportunities, and unwanted traffic force the entire site operation to go from hands-off to hands-on. Will the revenue model support this? Or will the time requirements force the entire operation to halt?
